本节内容:
1.字典介绍
2.字典增删改查和其他操作
3.字典的嵌套
一 字典的介绍
1.字典(dict) 是python中唯一的一个映射类型. 以{key:value}括起来的键值对组成.
2.键值对: key_value
key是唯一的. 是可哈希的,也就是不可改变的.
value无限制
已知可哈希的(不可变,作为key)的数据类型: int,str,tuple,bool
不可哈希的(可变的,不可作为key)数据类型: list,dict,set
3.语法: dic={key1:value,key2:value,...}
dict保存的数据是无序的,不能进行切片工作,只能通过key来获取字典中的数据

二 字典的增删改查(字典是无序的)和其他操作
1.增加
1) dict[不存在的key] = value #再次输入相同的key,会覆盖前面的数据

2) dic.setdefault(key,value) #如果再次输入相同的key,不会更改以前的数据

2.删除
1)dic.pop(key) #将key这一项对应的键值对删除,并返回键值对的value给ret

2)del dict[key] #将key对应的键值对删除

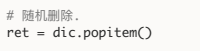
3)dic.popitem() #随机删除一对键值对
4)dic.clear() #清空字典,输出结果是 {}

3.修改
1)dict[存在的key] = 新value
2)d1.update(d2) #把d2的k-v键值对更新到d1中,d2不变,更新d1,如果存在了相同的key,则将d1中的value替换;否则,就添家加到的d1.

4.查询(一般用key来查找具体的数据,dic指已经定义的字典)
1) print(dic[key])

2) dic.get(key, 默认值)


3) a=dic.setdefault(key,value)
print(a)
# 1. 首先判断原来的字典中有没有这个key . 如果没有. 执行新增 # 2. 用这个key去字典中查询, 返回查到的结果

4) dict[key] #找到索引位置的元素
5.其他相关操作
1. keys() 返回所有字典的key的集合(高仿列表)

dic = { "及时雨":"宋江", "易大师":"剑圣", "维恩":"暗影猎手"}print(dic.keys()) # 拿到所有的key, 返回key的集合. 像是列表. 但不是列表. # 结果是:dict_keys(['及时雨', '易大师', '维恩'])for key in dic.keys(): # 可以进行迭代循环 print(key) # 输出所有的key 2. values() 返回所有的value的集合

dic = { "及时雨":"宋江", "易大师":"剑圣", "维恩":"暗影猎手"}print(dic.values()) # 高仿列表,可以进行迭代循环 结果: dict_values(['宋江', '剑圣', '暗影猎手'])for value in dic.values(): # 遍历打印出高仿列表里的value print(value) # 输出所有的value # 结果是: 宋江 剑圣 暗影猎手 3. items() 返回键值对. 元组

dic = { "及时雨":"宋江", "易大师":"剑圣", "维恩":"暗影猎手"}print(dic.items()) # 拿到键值对 # 结果是(高仿表):dict_items([('及时雨', '宋江'), ('易大师', '剑圣'), ('维恩', '暗影猎手')])for k, v in dic.items(): # 遍历dict,输入键值对 print(k , v) ''' 结果是: 及时雨 宋江易大师 剑圣维恩 暗影猎手 ''' 4.解构:(解包)
a, b = (1, 2)print(a,b) #1 2
a, b = (1, 2)print(a) #1print(b) #2
a, b, c = ("马化腾", "马云", "马良")print(b) #马云 a, b = [1, 2]print(a, b) #1 2
三 字典的嵌套
# 字典的嵌套dic = { "name":"汪峰", "age": 58, "wife":{ "name":"国际章", "salary": 180000, "age": 37 }, "children":[ { "name":"老大", "age": 18}, { "name":"老二", "age": 118} ]}print(dic["children"][1]["age"]) #118print(dic["wife"]['salary']) #180000 四,字典的遍历
dic = {1: 'a', 2:'b', 3:'c'}for a in dic: # 直接循环字典.拿到的是key print(a) #1 2 3 key print(dic[a]) #a b c value